
Process Modelling
Modellazione dei sistemi a grande numero di gradi di libertà
Nel processing dei dati industriali, avere a che fare con un insieme molto numeroso di variabili di controllo è davvero una brutta gatta da pelare!
Oggigiorno, con l’avvento di nuove filosofie di sviluppo che sono strategicamente orientate al dato (data oriented) piuttosto che al prodotto (product oriented), non è difficile trovare casi in cui il numero di gradi di libertà del sistema (in gergo si chiamano anche KPV, Key Process Variable) supera il centinaio.
Nel settore chimico, meccanico, aerospaziale - la cosa non fa la minima differenza, credetemi – il maggior controllo del processo attraverso un sistema capillare di sensori con dinamiche di acquisizione spinte ( i.e. molti campioni temporali per ricostruire il segnale da monitorare) rende tutto operativamente più complicato.
Questa è, per contro, la ragione vera che fa la differenza. Disporre di molti dati, in termini di molte KPV osservate nel tempo, serve ed è utile ma solo se tali dati li sappiamo analizzare. Altrimenti, si tratta solo una complicazione formale che, alla luce di un fenomeno matematico che si chiama esplosione combinatoria, avrà fatto spendere molti denari per il data retrieval (raccolta dati) con il risultato di avere un inefficiente data mining (analisi dei dati, ex post). Da un semplice e banale esempio di osservazione di KPV che intende dare, ad esempio, una caratterizzazione di certi fenomeni settore farmaceutico, possiamo comprendere il succo della questione.
Supponiamo di osservare in un reattore a pressione e temperatura controllate (l’evoluzione di quello un tempo era, nelle antiche erboristerie dei monasteri medioevali, un semplice vasetto di terracotta), il comportamento di un farmaco che dipende dalla concentrazione delle specie reagenti, dalla pressione dalla temperatura e da altre variabili di controllo che il tecnico di turno (supporremo l’erede di frate Severino de “Il nome della rosa” alias l’erborista, lo ricordate?) desidera controllare.
Il tecnico predispone l’osservazione - diciamo - di quindici KPV per due mesi dopo di che mette su un modello ricordando quello che ha imparato al corso di statistica sulle RSM (Response Surface Method). Egli ottiene un semplice sistema algebrico lineare del tipo Ax=y in cui A è la matrice delle osservazioni, x sono i coefficienti di una superficie di risposta ed y i termini noti.
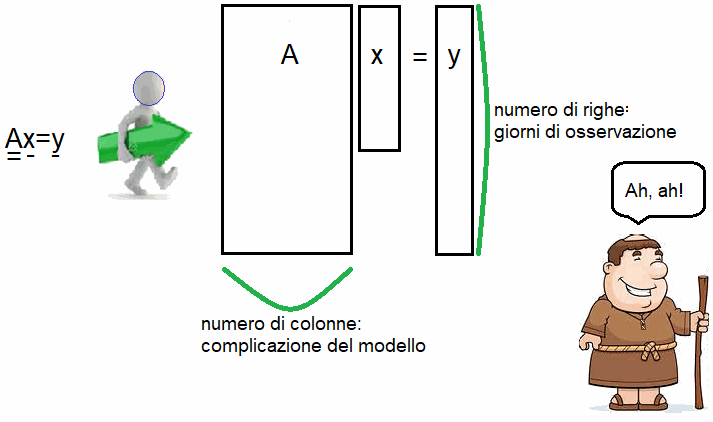
Il problema dal punto di vista della geometria della matrice si dice rettangolare allungato perché ci sono quindici colonne e sessanta righe. In gergo si dice che il sistema è sovradeterminato perché ci sono molte più equazioni di quelle necessarie (più equazioni che incognite).
Il povero tecnico, pensando di avere un modello nettamente più scientifico e performante di quello di fra’ Severino, cerca di analizzare i dati ma diventa l’artefice di un grande insuccesso.
Che cosa è accaduto? Egli ha lavorato con variabili probabilmente importanti a caratterizzare il comportamento del farmaco ma le ha gestite con il modello sbagliato (i.e. il metodo LS di tipo unweighted, un classico metodo dell’algebra lineare) introducendo rumore e producendo, alla fine della storia, una prestazione più bassa di quella che fra’ Severino, con meno variabili e meno osservazioni ha più correttamente realizzato.
Ciò è quello che succede sistematicamente nel settore dei big data ovvero, semplicemente, quando si fanno ipotesi sbagliate per caratterizzare un fenomeno semplice che, invece, semplice non è. Nella figura di sotto potete osservare un po’ l’evoluzione di un’ analisi tipica di fenomeni che hanno una dipendenza - si dice in gergo – multivariata vale a dire che non dipendono mai da una sola variabile ma, tipicamente, da molte variabili.

Ebbene, se quel “molte” diventano “moltissime” oppure se semplicemente il numero di osservazioni a disposizione è elevato, occorre fare una serie di passaggi obbligati fra cui l’analisi sulla riduzione dello spazio delle KPV, l’analisi delle componenti principali lineari, l’analisi delle componenti principali non lineari solo per citarne alcune ma anche, last but not least, l’applicazione di metodi molto più sofisticati basati sull’intelligenza artificiale, quali le reti neurali e, in senso lato, gli algoritmi genetici.
Questo, tipicamente, succede quando l’insieme dei dati è piuttosto importante e quando la simulazione di processo, ad esempio tramite la CFD (Computational Fluid Dynamics) se si tratta di un fenomeno modellabile con fluidi e solidi, da sola non è sufficiente a catturare l’essenza dei fenomeni di campo perché anche la modellazione, da sola, risulta essa stessa ancora troppo onerosa per l’elevato numero di esperimenti da fare, anche con una filosofia di tipo DoE (Design of Experiments) al posto di prove di tipo OFAT (One Factor a Time).
Di recente, si è fatta strada la moda di parlare anche di sistemi di tipo back swan (cigno nero) e questo, purtroppo, da quando si è avuta la nefasta e perniciosa presenza del coronavirus nella nostra società. In soldoni, i fenomeni di tipo black swan sono quei fenomeni che sono altamente improbabili secondo la statistica classica perché la “statistica classica” impiega modelli decisamente semplificati ovvero semplicemente miopi sotto certi punti di vista. A proposito de “Il nome della rosa”, ricordate il “Rasoio di Occam” di frate Guglielmo? Numquam est ponendum praeter necessitatem, vale a dire “utilizza modelli semplici… ma solo finché puoi!”
Il trucco è proprio questo, capire quando un modello è troppo semplice per essere sempre valido. Oggi, nel settore della simulazione di processo industriale, si parla necessariamente di approccio sinergico fra la modellazione diretta (la classica CFD o la modellazione strutturale) e modellazione funzionale vale a dire la scienza che, con tutti i possibili strumenti, mette a disposizione del modellista di processo la caratterizzazione di un fenomeno in funzione di certe ben precise KPV in quella che si chiama macromolecola computazionale locale.
Forse oggi è davvero l’era di un cambiamento sostanziale delle strategie previsionali (ricordiamo il non secondario problema delle Time Series che pure è fondamentale nel settore modellistico) basandosi sulla considerazione di tutte quante le variabili di controllo, almeno in prima istanza, cosi come testimoniato dallo scrittore Andrea Camilleri che, facendo parlare un personaggio della serie il commissario Montalbano, gli fa dire :”Vede, signor commissario. Io mi sono fatto persuaso che ciò che differisce gli uomini dai mezzi uomini sia la capacità di pensare che tutto sia importante. Anche le cose che non significano niente!”.